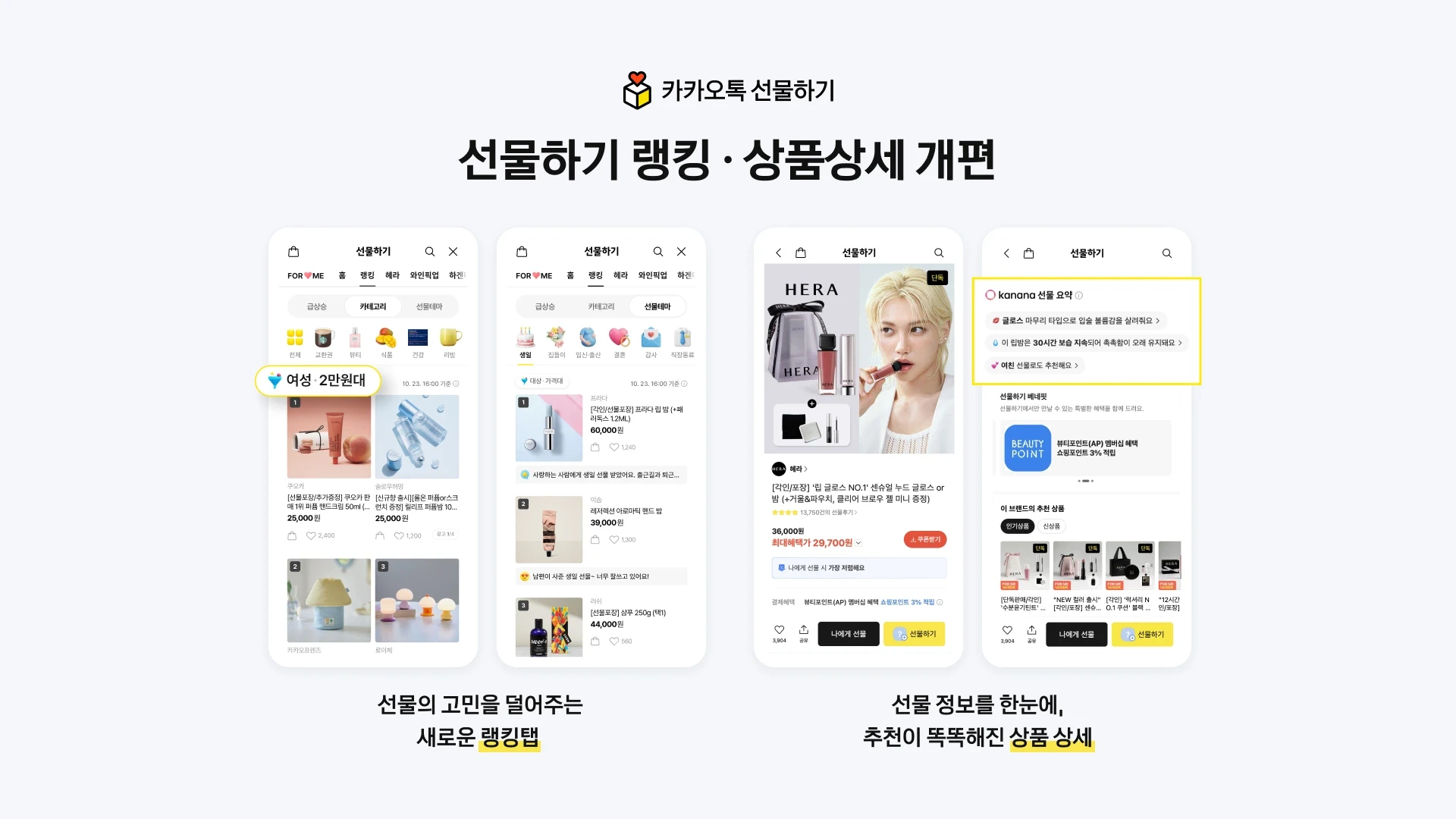
meta, SAM Audio 통합 멀티모달 모델 공개
AI 요약
Meta가 오디오 편집의 패러다임을 바꿀 'SAM Audio(Segment Anything Model Audio)'를 공개하며, 복잡한 음원 혼합물에서 텍스트·비주얼·시간 범위 프롬프트로 특정 소리를 정밀하게 분리하는 세계 최초의 통합 멀티모달 모델을 선보였습니다.
SAM Audio는 올해 초 공개된 Perception Encoder 모델을 기반으로 한 Perception Encoder Audiovisual(PE-AV) 엔진을 핵심으로, "기타 리프만 추출해"나 비디오에서 기타리스트 클릭, 파형 특정 구간 하이라이트 같은 직관적 입력만으로 타겟 소리와 잔여 음원을 동시에 고품질로 생성합니다.
Flow-matching Diffusion Transformer 아키텍처와 DAC-VAE 잠재 공간을 활용해 기존 전문 음악 분리 시스템을 능가하는 벤치마크 성능을 달성했으며, 연주·보컬·음성·환경음 등 다양한 실세계 시나리오에서 안정적으로 작동하는 점이 차별화 포인트입니다.
Meta는 SAM Audio를 오픈소스로 공개하며 Perception Encoder 모델·벤치마크 데이터셋·연구 논문까지 함께 배포해 개발자들이 콘텐츠 제작·접근성 향상·오디오 분석 등 새로운 AI 애플리케이션을 구축할 수 있도록 지원합니다.
예를 들어 팟캐스트 배경 소음 제거, 라이브 공연 특정 악기 추출, 영화 사운드 디자인에서 원하는 효과음 정밀 편집 등 기존에 수작업으로만 가능했던 작업을 프롬프트 한 번으로 해결하며, 실시간 처리 최적화로 NVIDIA A100 같은 GPU에서 효율적으로 동작합니다.
SAM 시리즈의 이미지·비디오 세그멘테이션 성공을 오디오 영역으로 확장한 이번 모델은, 앞으로 멀티모달 AI 시스템과 결합해 풀 오디오-비주얼 편집 스위트로 진화할 전망이며 McKinsey 보고서에서 예측한 생성 미디어 기술 20% 연평균 성장에 기여할 것으로 보입니다.
누구나 Segment Anything Playground에서 바로 체험 가능하며, 오픈소스 커뮤니티 피드백을 통해 모호한 프롬프트·희귀 사운드 처리 등 한계를 극복하며 오디오 AI 생태계의 새로운 표준으로 자리 잡을 가능성이 큽니다.